Covid19-Letalität: Den Daten auf der Spur

Wie hoch ist das Risiko, an COVID19 zu sterben? Ist eine Aussage dazu aufgrund der aktuellen Datenlage in Deutschland möglich? Peter Steinbach vom Helmholtz-Zentrum Dresden-Rossendorf sucht nach Antworten und führt eine Datenanalyse durch.

Die Bilder von COVID19-Toten in Italien, China, Spanien oder New York sind mir nicht aus dem Kopf gegangen. Als Datenwissenschaftler bin ich jedoch trotz der Angst immer daran interessiert, mir das Geschehen anhand der Zahlen so objektiv wie möglich vor Augen zu halten. Wie viele andere Menschen auch, habe ich den Wunsch, die Bedrohung durch COVID19 genau einzuordnen.
Inspiriert durch einen Blogpost des Risikoforschers Sir David Spiegelhalter würde ich gern wissen: Wie hoch ist das Sterberisiko durch COVID19? Dazu noch: Ist eine Aussage dazu mit den aktuell öffentlich-zugänglichen Daten für einen Datenwissenschaftler überhaupt möglich? Im Folgenden will ich diesen Fragen nachgehen. Bevor wir uns in die Daten stürzen, will ich allerdings betonen, dass ich weder Virologe noch Epidemiologe bin.
Der Datensatz
Zum Zeitpunkt, als ich diesen Artikel erstellt habe (29.5.2020), meldete das Robert-Koch-Institut (RKI) 180 458 positiv getestete SARS-CoV-2-Fälle in ganz Deutschland. Dieser Datensatz wird mir als Grundlage für alle weiteren Betrachtungen dienen. Die Daten des RKI bilden die amtlichen Meldeergebnisse der Gesundheitsämter ab. Damit sind sie per Definition für mich (trotz aller Kritik) vertrauenswürdig. Zudem zeigen die RKI-Daten die Fallzahlen pro Altersgruppe, was für diesen Artikel wichtig ist. Diese Information ist weder in den Daten der Johns Hopkins University noch im Risklayer-Datensatz enthalten.
Allerdings wissen wir auch, dass in diesen Zahlen nicht alle Infizierten verzeichnet sind. Die Symptomatik von COVID19 zeigt eine Großzahl von Verläufen mit milden oder unmerklichen Symptomen. Diese leichten Fälle werden sicherlich nicht diagnostiziert: Wer keine Symptome hat, geht nicht zum Arzt. Später werde ich auf diese Unzulänglichkeit in den Datensätzen noch weiter eingehen. Zunächst arbeite mit den Daten, welche die Grundlage der öffentlichen Diskussion sind.
Den Datensatz des RKI habe ich mit Hilfe von Open-Source-Software gewonnen. Für diesen Post benutze ich die Programmiersprache R und zwei dazugehörige Bibliotheken, tidyverse und covid19germany. Der Quelltext dieses Artikels ist in diesem Repository einsehbar.
Bevor ich die Analyse beginnen kann, muss ich mich versichern, dass die Daten sauber sind. Mit dieser Aufgabe verbringen viele Data Scientists den Hauptteil ihrer Arbeit. Im Falle des RKI-Datensatzes hat diese Arbeit bereits das Paket covid19germany kurz nach dem Download übernommen, welches im Kontext des #WirvsVirus-Hackathons der Bundesregierung entwickelt wurde.
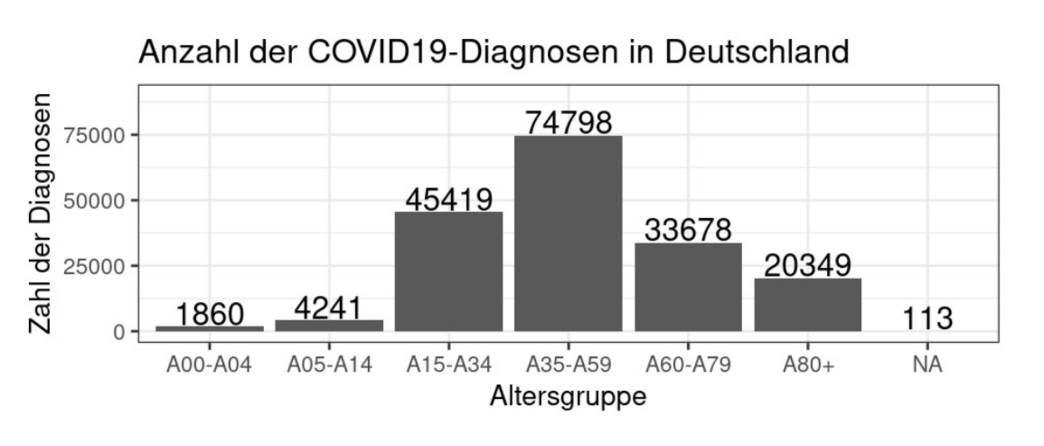
Hier fallen gleich mehrere Dinge auf:
- Das RKI benutzt ungleich eingeteilte Altersklassen, genauer Altersspannen von 5, 10, 20, 25, 20, unendlich Jahren. Nach Aussage des ESRI-Supports (der die Daten im Internet zur Verfügung stellt) folgt diese Einteilung „epidemiologischer Logik“.
- Es gibt Patienten, deren Alter nicht bekannt ist. Diese werden mit dem Wert NA (engl. „Not Available“) bezeichnet.
- Nur 113 Einträge von insgesamt 180 458 Einträgen sind als NA markiert – ein eher verschwindend geringer Teil von 0,06 Prozent.
- Interessant ist: Die meisten Diagnosen gibt es in der Altersgruppe von 35–59 Jahren. In dieser Altersgruppe befinden sich aber generell die meisten Menschen in Deutschland.
Mortalitäten
„Der Mensch soll um der Güte und Liebe willen dem Tode keine Herrschaft einräumen über seine Gedanken.“ Thomas Mann, Der Zauberberg
Zur Einschätzung des maximalen Risikos, durch den Corona-Virus zu sterben, hilft vielleicht ein Vergleich mit der Sterblichkeit der deutschen Gesamtbevölkerung. Letztere ist in der Sterbetafel (Daten für Deutschland) des statistischen Bundesamtes wiedergegeben.
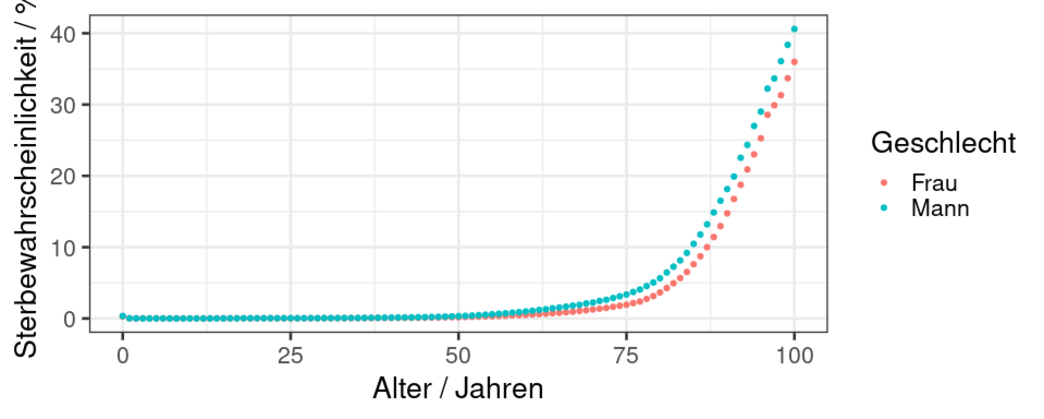
Diese Grafik muss erklärt werden! Das statistische Bundesamt hat im Zeitraum von 1991 bis 2018 darüber „Buch geführt“, in welchem Alter Menschen in Deutschland (Männer und Frauen separat) zu Tode kommen. Das wird oft anhand von repräsentativen Kohorten gemacht. Pro Lebensjahr wurde gezählt, wie viele Menschen insgesamt in die Datenerhebung eingehen und welche in diesem Lebensjahr ihr Leben lassen. Teilt man die Gesamtzahl aller Todesfälle eines Lebensjahres im genannten Zeitraum durch die Gesamtmenge des gleichen Lebensjahres (egal ob verstorben oder nicht), erhält man die Todeshäufigkeit pro Lebensjahr.
Die Themenseite des statistischen Bundesamtes veröffentlicht leider nicht die genauen Details der Berechnung der Sterbetafel – was aber im Sinne von OpenData und OpenScience nur wünschenswert wäre. Ein Beispiel zur Illustration hilft hier: 1000 Frauen werden 65 Jahre alt. Im Laufe des Jahres sterben 8 Frauen. Die Sterbewahrscheinlichkeit für Frauen dieser Kohorte ist also 0,8 Prozent.
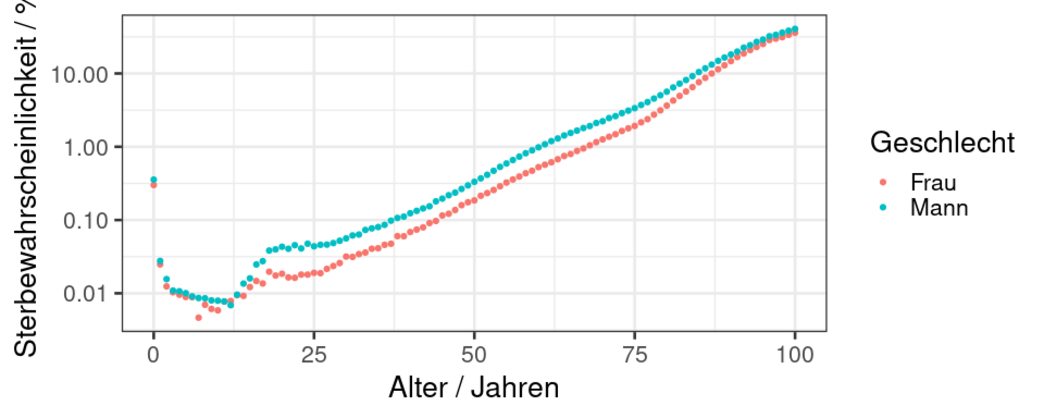
Wird die Y-Achse wie hier logarithmisch transformiert, werden noch mehr Eigenschaften der Kurve sichtbar, die charakteristisch für unsere Lebensweise ist. Man benutzt diese Transformation, um das Verhalten insbesondere bei niedrigen Werten der Sterbewahrscheinlichkeit zu „sehen“.
Wollten wir nicht über COVID19 sprechen?
Natürlich! Um ein besseres Gefühl für die Bedrohung von COVID19 zu bekommen, kann ich aus den Daten des RKI eine Fallsterblichkeit (auch Letalität oder „case fatality rate“ genannt) berechnen. Das bedeutet, ich teile die Zahl der an COVID19-Verstorbenen (entsprechend der Definition des RKI) durch die Zahl der insgesamt diagnostizierten SARS-CoV-2-Fälle. Wenn ich das pro Altersgruppe durchführe, bekomme ich die unkorrigierte Fallsterblichkeit je Altersgruppe der COVID19-Patienten:
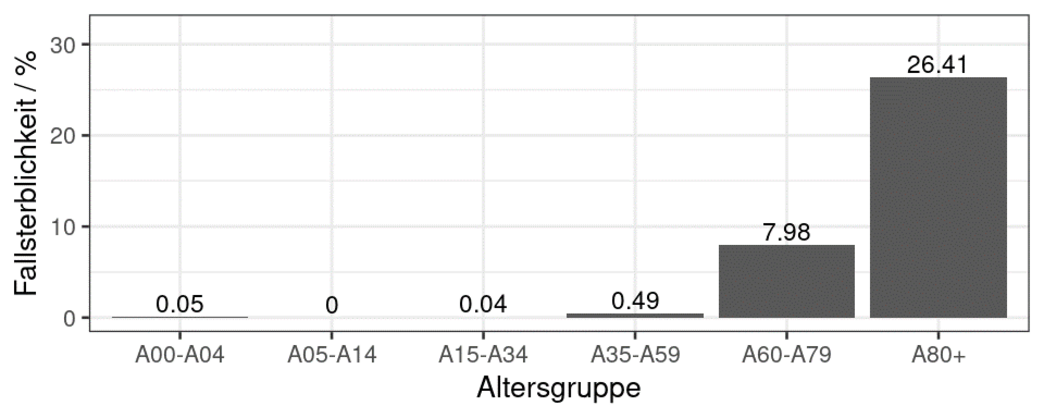
Im Diagramm oben haben wir zwei Mengen durcheinander geteilt: die Häufigkeit(en) von Toten unter den diagnostizierten Fällen geteilt durch die Gesamtzahl aller positiv Diagnostizierten. Das ist eine einfache mathematische Operation, die hier für jede Altersgruppe durchgeführt wird.
Wenn wir an dieser Stelle weitermachen, sollte allen Lesern klar sein, dass wir dem Fehlerteufel eine Einladung erteilen. Obigen Zahlen blind zu vertrauen wäre falsch. Ein Grund dafür ist, dass die Pandemie zum Zeitpunkt der Veröffentlichung nicht vorbei ist. Es liegen immer noch Patienten in Krankenhäusern, deren Schicksal unbekannt ist. Typischerweise werden Letalitäten nach einer Pandemie bestimmt.
Ultimativ wollte ich ja gern wissen, wie wahrscheinlich es für positiv diagnostizierte – oder noch besser für infizierte – Bürger ist, an COVID19 zu sterben. Das ist zwar drastisch, denn niemand will gern sterben. Dafür ist die Zahl der Toten leicht zählbar. Statistisch gesehen ist das aber leider nicht leicht. Denn wir brauchen einen sogenannten Schätzer, um die Brücke von den Daten zu den Eigenschaften der Erkrankung für die gesamte deutsche Bevölkerung zu schlagen. Ein Schätzer ist die mathematische Beschreibung unseres Wissens und drückt die Vermutung aus, wie sich die Daten bzw. die Wirklichkeit verhält.
"Ultimativ wollte ich ja gern wissen, wie wahrscheinlich es für positiv diagnostizierte – oder noch besser für infizierte – Bürger ist, an COVID19 zu sterben. Das ist zwar drastisch, denn niemand will gern sterben."
Peter Steinbach, Leiter des Helmholtz AI Consultant Teams am Helmholtz-Zentrum Dresden-Rossendorf
Ein weiteres Problem ist: Die Grundmenge an Personen, welche auf SARS-CoV-2 getestet wurden, ist in den RKI-Daten nicht repräsentativ verteilt. Durch die Regeln, wer getestet werden darf und soll, decken die Daten hier keine zufallsbasierte Stichprobe der Bevölkerung ab. Interpretationen dieser Zahlen können also nicht hundertprozentig Rückschlüsse auf Deutschland erlauben. Unser Schätzer hätte also einen starken Sampling Bias. Man sieht also, wie wichtig zufallsbasierte Kohortentests auf SARS-CoV-2 sind. Dieser Gedanke ist schon Anlass für weitere Studien durch das Helmholtz-Zentrum für Infektionsforschung.
Die Sterblichkeit ist das Verhältnis der Zahl der toten COVID19-Positiven zu allen COVID19-Positiven. Die Betrachtung eines Verhältnisses kann Unzulänglichkeiten im Spannungsfeld zwischen der Zahl der Diagnostizierten und der Zahl der Infizierten insgesamt umgehen. In bester Näherung ist die Zahl der Toten aus der Zahl der Diagnostizierten entnommen und wir hoffen, dass dieses Verhältnis auch nicht viel anders ist, wenn man die Zahl aller Infizierten zugrunde legen würde.
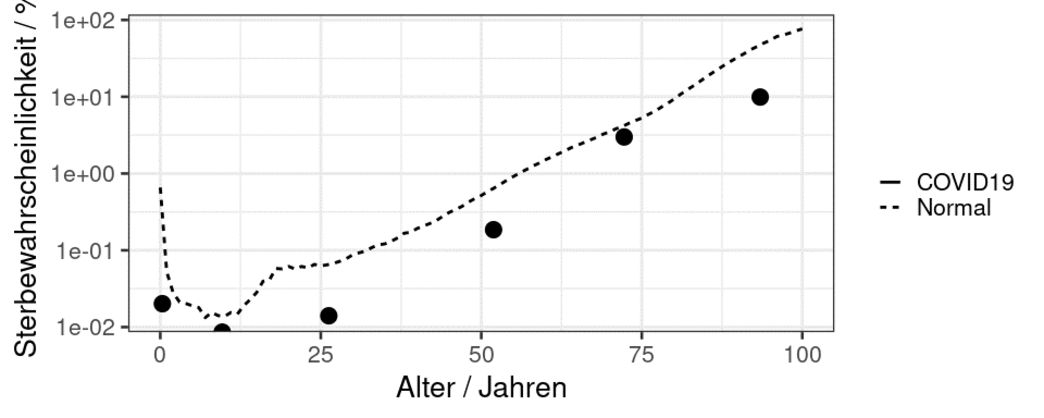
Anhand der RKI-Daten, kann ich die COVID19-Fallsterblichkeit aus dem RKI-Datensatz nun mit der durchschnittlichen Normalsterblichkeit in Gesamtdeutschland vergleichen und in einem Diagramm visualisieren. Dafür zeichne ich am Punkt des mittleren Alters je Altersgruppe, wo das gewichtete Mittel der Normalsterblichkeit liegt, die Fallsterblichkeit ein.
Um die Altersgruppenintervalle kenntlich zu machen, habe ich die Datenpunkte mit horizontalen Balken versehen, die sich über die gesamte Breite eines Altersintervalls erstrecken. Dies soll visuell unterstreichen, wo mir Daten fehlen und sich eine Unsicherheit ergibt.
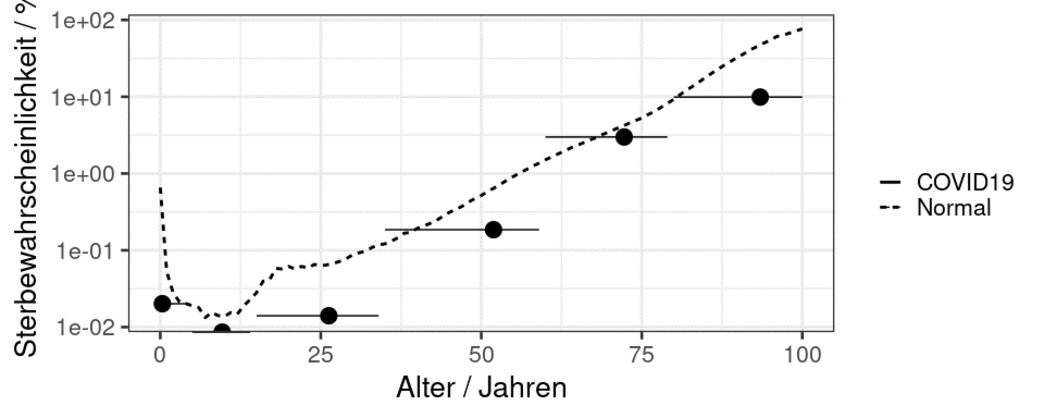
Nach einer italienischen Studie über die Bekämpfung eines COVID-19-Ausbruchs in der Gemeinde Vo bei Padua könnten ca. 41–45 Prozent aller Infizierten asymptomatisch sein (die Mortalität wäre also nur halb so hoch wie die Fallsterblichkeit). In der Heinsberg-Studie von Streek et al. wird von 30 Prozent der Fälle gesprochen. Diesen Aspekt müssen wir in der Untersuchung der Sterblichkeit berücksichtigen.
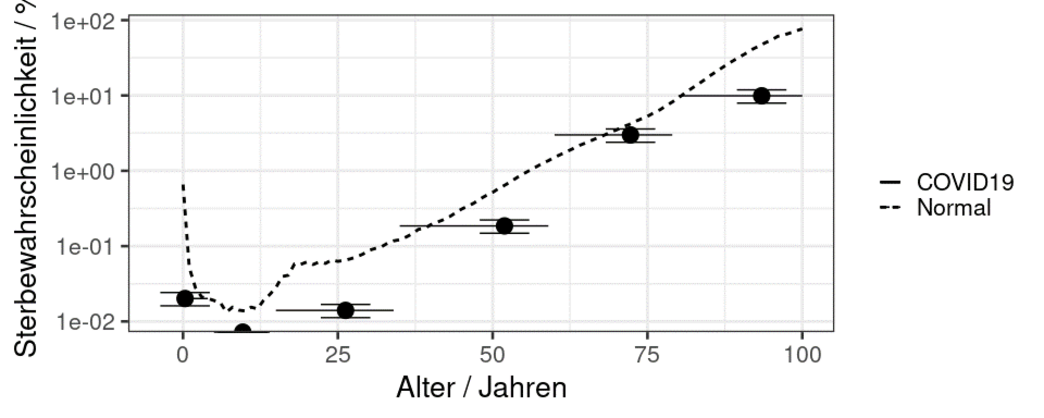
Dafür führe ich in obigem Diagramm eine Unsicherheit bzgl. der Sterblichkeit aufgrund der heterogenen Publikationslage ein und illustriere sie mit vertikalen Balken. (In der Grafik können diese aufgrund ihrer geringen Größe leider nicht gut dargestellt werden, daher sind mit den kleinen horizontalen Balken lediglich die Endpunkte dieser Vertikalen markiert.) Als zentralen Wert nutze ich den mittleren Wert zwischen 30 und 45 Prozent.
Sensitivität und Spezifizität des SARS-CoV-2-Tests, der zur Erstellung der Diagnose benutzt wird, stellt eine weitere Quelle für nötige Korrekturen dar. Dieser Labortest ist wie viele andere nicht perfekt. Leider kann ich eine Korrektur darauf hier nicht anwenden, da ich nicht die Zahl der durchgeführten Tests insgesamt kenne. Es gibt bisher nur Gesamtzahlen pro Woche im Epidemiologischen Bulletin des RKI. Das ist also eine weitere Beschränkung des Datensatzes. Zudem ist die Spezifizität der PCR-Diagnostik nach meinem Kenntnisstand nicht publiziert.
Neben diesen beiden Unsicherheitsquellen gibt es noch viele weitere, welche in einer echten Analyse untersucht, dokumentiert und als Fehlerbalken oder Korrektur auf die Daten Einfluss nehmen. In meiner Darstellung hier habe ich mich auf diese beiden zur Illustration beschränkt. Ich betone hier klar, dass die Präsenz von Unsicherheitsintervallen kein Indiz für ein Irren ist. Im Gegenteil hebt sich jede Datenanalyse positiv ab, wenn Unsicherheiten der Daten klar benannt, studiert und visualisiert werden.
"Nein, mit diesem Datensatz können wir keine absolute Aussage über das Risiko machen, an COVID19 zu sterben. Der Verlauf der COVID19-Fallsterblichkeit in den Diagrammen kann aber ein Gefühl für das Verhalten der Krankheit geben."
Peter Steinbach, Leiter des Helmholtz AI Consultant Teams am Helmholtz-Zentrum Dresden-Rossendorf
Äpfel und Birnen?
Was heißt das nun: Ist COVID19 gar nicht so schlimm, da es bzgl. der Sterblichkeit vergleichbar mit der regulären Sterblichkeit zu sein scheint? Oder vergleichen wir hier Äpfel mit Birnen? Können wir der Frage mit Data Science näherkommen?
Die Mortalität ist eine Eigenschaft des Sars-Cov-2-Virus und wie er auf den infizierten Menschen wirkt. Durch die Art und Weise, wie der RKI-Datensatz entstand, können wir daraus nur eine mögliche Fallsterblichkeit ermitteln, die nicht repräsentativ für die gesamte deutsche Bevölkerung ist. Die absoluten Werte der beiden Sterblichkeiten (Fallsterblichkeit und Normalsterblichkeit) anhand der RKI-Daten sind nicht vergleichbar. Hier haben wir also unser Fallobst aus der Überschrift und wir kommen zu dem Schluss: Nein, mit diesem Datensatz können wir keine absolute Aussage über das Risiko machen, an COVID19 zu sterben.
Der Verlauf der COVID19-Fallsterblichkeit in den Diagrammen kann aber ein Gefühl für das Verhalten der Krankheit geben. Wie die Daten zeigen, tragen Menschen in höheren Altersgruppen mehr Sterberisiko. Dies deckt sich mit den medizinischen Beobachtungen, dass vor allem Menschen mit Vorerkrankungen (und die haben eher ältere Mitmenschen) dem Virus erliegen. Es schließt aber ganz klar jüngere Menschen nicht aus, denn die Letalität ist auch in den jungen Altersgruppen nicht 0!
Diese Interpretationen ersetzen keinesfalls die medizinische Diagnostik oder die exzellenten virologischen und epidemiologischen Studien von Wissenschaftler*innen aus Deutschland und anderen Ländern. Immerhin ist die angewandte Statistik heute Teil fast jeder wissenschaftlichen Disziplin, so auch der Virologie. Nach meinem Einblick besteht die Epidemiologie fast vollständig aus angewandter Mathematik – wie es Statistik und Data Science sind. Wie sich aber klar zeigt, ist der Weg von den Daten zu einer Erkenntnis und zu Wissen steinig und in einem Blog wie diesem nicht machbar. Hierfür braucht es fachliches Wissen und Erfahrung – angefangen bei biologischen und medizinischen Aspekten, über die Datennahme, Diagnostik hin zur Datenauswertung und Modellierung inklusive der Unsicherheiten innerhalb all dieser Schritte. Letzteres kann dieser Artikel aus Platzgründen nur andeuten.
Mir persönlich hat diese Analyse mehr Überblick über die Lage gebracht. Auch wenn ich zur Altersgruppe A35-69 gehöre und scheinbar wenig Risiko trage, weiß ich nun, dass mich das nicht hundertprozentig schützen kann. Ganz plastisch sehe ich in den Darstellungen oben, wie sehr meine eigene Disziplin im Home Office zur Gesundheit meiner (vor allem älteren) Mitbürger*innen beiträgt. Diesen Beitrag an Stress und Zusatzbelastung durch Telearbeit und Home Schooling leiste ich sehr gern.
Dank
Ich bedanke mich bei Dr. Stefan Müller vom HZDR für wichtiges Feedback und Korrekturvorschläge zu diesem Artikel.
Autor: Peter Steinbach