
Unser Partner im Süden: Helmholtz Munich widmet sich der Erforschung weit verbreiteter Krankheiten wie Diabetes, Allergien und ähnliches und untersucht deren Entstehung im Zusammenspiel von Umweltfaktoren, Lebensgewohnheiten und genetischer Prädisposition.


Die Programme
Mit HIDA Helmholtz Munich kennen lernen
Über die Helmholtz-Gemeinschaft
Die Helmholtz-Gemeinschaft ist die größte Wissenschaftsorganisation Deutschlands. Unsere übergreifenden Forschungsprogramme verbinden die 18 Helmholtz-Zentren miteinander.
Jedes Zentrum verfügt über eigene wissenschaftliche Schwerpunkte und Infrastrukturen. Die Forschung ist thematisch in sechs strategische Bereiche gegliedert.
- Energie
- Erde und Umwelt
- Gesundheit
- Information
- Luftfahrt, Raumfahrt & Verkehr
- Materie
Bei Helmholtz Munich wird der Frage nachgegangen, wie Diabetes, Allergien und chronische Lungenleiden durch Umwelteinflüsse ausgelöst werden. Die so gewonnenen Erkenntnisse nutzen die Wissenschaftler, um innovative Therapieansätze und neuartige Arzneimittel zu entwickeln. Ziel von Helmholtz Munich ist es, umweltbedingte Krankheiten besser zu verstehen, um neue Wege in der Diagnostik, Therapie und Prävention zu gehen.
Forschungsschwerpunkte:
- Erforschung von Volkskrankheiten (Diabetes, Allergien, chronische Lungenkrankheiten)
- Analyse der Faktoren Umwelt, Lebensstil und genetischer Disposition
- Prävention und Diagnostik
- Arzneimittelforschung

Die Standorte
Die Standorte
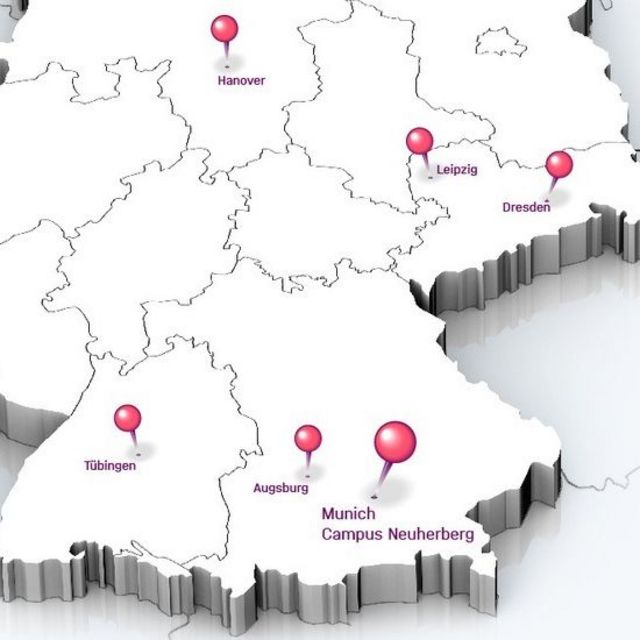
Helmholtz Munich ist an mehreren Forschungsstandorten aktiv:
- Neuherberg (Hauptstandort)
- Großhadern
- München Stadt
- Augsburg
- Tübingen
- Hannover
- Dresden
- Leipzig
Kompetenzen des Helmholtz Munich im Bereich Data Science und KI
In einem interdisziplinären Umfeld entwickeln Data Scientists bei Helmholtz Munich zukunftsweisende KI-Modelle und analytische Werkzeuge, die entscheidend zur Lösung komplexer Gesundheitsfragen beitragen.
Der Fokus der Forschung umfasst die Integration von Multi-Omics-Daten, KI-gestützte Bildverarbeitung, personalisierte medizinische Anwendungen und die Untersuchung von Umwelt-Gesundheit-Interaktionen. Helmholtz Munich engagiert sich durch skalierbare Dateninfrastrukturen und Open-Science-Initiativen für die Förderung von Gesundheit und Lebensqualität auf breiter Basis.
- Biomedizinische KI und Maschinelles Lernen
- Integration und Analyse von Multi-Omics-Daten
- KI-gestützte Bildverarbeitung und -analyse
- Digital Health und Personalisierte Medizin
- Skalierbare Dateninfrastruktur und Open-Science-Initiativen
- KI für Umwelt- und Gesundheitsschnittstellen
Bei Helmholtz Munich arbeiten Menschen aus 88 Nationen. Insgesamt sind an den Standorten in Deutschland 2515 Mitarbeitende tätig.
Bewerbung
Sie möchten an der Helmholtz Munich forschen und arbeiten? Dann bewerben Sie sich jetzt für das HIDA Mobility Program!
Kontaktieren Sie Ihren potenziellen Betreuer oder Ihre potenzielle Betreuerin bitte vorab per E-Mail, um ein Forschungsprojekt vorzuschlagen und zu besprechen. Reichen Sie erst nach dieser Klärung Ihre Bewerbung ein.
Weitere Informationen zu den Bewerbungsregularien finden Sie hier!
Hinweis für externe Bewerber:
Bei Fragen zu Bewerbungsformalitäten und organisatorischen Abläufen wenden Sie sich bitte direkt an Ihr Heimatinstitut.
Die Hosts am Helmholtz Munich
Lernen Sie hier einige potentielle Gastgeberinnen und Gastgeber bei Helmholtz Munich kennen und erfahren sie mehr über deren jeweilige Data Science-Forschung.
Bitte beachten Sie: Die hier aufgeführte Liste zeigt lediglich eine Auswahl möglicher Gastgeber.
Darüber hinaus können Sie auch eigenständig potenzielle Hosts im Zentrum kontaktieren und mit ihnen eine Teilnahme am HIDA Mobility Program vereinbaren.
Wenn Sie Fragen haben, senden Sie bitte eine E-Mail an: hida@helmholtz.de
Sie möchten selbst gerne Helmholtz-Gastgeber werden und suchen nach Unterstützung für Ihr Forschungsprojekt? Dann wenden Sie sich ebenfalls an die oben genannte E-Mail Adresse.

Julia Schnabel
Computational Imaging and AI in Medicine
Ansprechpartner
Short summary of your group's research: The Institute of Machine Learning in Biomedical Imaging (IML) focuses on research to leverage machine learning for the grand challenges in biomedical imaging in areas of unmet clinical need. Its goal is to fundamentally transform the use of imaging for diagnostics and prognostics. Novel and affordable solutions should empower clinics to make more accurate, fast and reliable decisions for early detection, treatment planning and improved patient outcome.
What infrastructure, programs and tools are used in your group? Novel and affordabel solutions should empower clinics to make more accurate, fast and reliablie decisions for early detection, treatment planning and improved patient outcome.
What could a participant of a HIDA mobility program learn in your group? How could he or she support you in your group? Deep learning and machine learning methods for intelligent imaging solutions, from imaging sensor to clinical applications

Bastian Rieck
AIDOS Lab at the Institute of AI for Health
Ansprechpartner
Short summary of your group's research: Our primary research interests are situated at the intersection of geometrical deep learning, topological machine learning, and representation learning. We want to make use of geometrical and topological information—also known as manifold learning—to imbue neural networks with more information in their respective tasks, leading to better and more robust outcomes. Following the dictum ‘theory without practice is empty,’ we also develop methods to address current challenges in biomedicine or healthcare applications.
What infrastructure, programs and tools are used in your group? HPC CPU/GPU cluster using Slurm, machine learning frameworks (mostly pytorch) and data analysis tools (scikit-learn, pandas, numpy) based on Python. On the theory side, we are world leaders in topological machine learning, as nascent branch of machine learning.
What could a participant of a HIDA Mobility Program learn in your group? How could he or she support you in your group? Getting to know cutting-edge AI research in geometrical deep learning or topological machine learning, including—but certainly not limited to—graph representation learning. At HMGU, we are sitting on a treasure trove of complex high-dimensional data sets, bearing the promise to substantially advance our understanding of disease-driving mechanisms, for instance. Visitors will benefit from being exposed to a unique combination of theory and practice, with the prospect of working on challenging, impactful applications. We need motivated doctoral researchers who can support our endeavour of developing the next generation of machine learning models to boldly tackle the challenges of today and tomorrow in healthcare!

Carlos Talavera-López
Computational Immunobiology
Ansprechpartner
Short summary of your group's research: Our lab specialises in translational single cell biology with focus on infectious diseases. We develop integrative Carlos Talavera-LópezAI approaches to characterise cellular behaviour in health and disease with the aim of identifying diagnostic biomarkers that can be easily deployed in the clinic.
What could a participant of a HIDA Mobility Program learn in your group? How could he or she support you in your group? We are looking for a curious, dedicated scientist interested in learning to apply AI/ML methods to single cell multiome data, and to help us find ways to better communicate biological insights using novel data visualisations. Together, we will better understand the cellular social networks of inflammatory processes, and how these interactions could be potentially be used as diagnostic biomarkers.

Christian L. Müller
Biomedical Statistics and Data Science
Ansprechpartner
Three-sentence summary of your group's research: We do research in high-dimensional statistics, (non-)convex optimization, network inference, causal inference, and compositional data analysis with a special interest in microbiome research and microbial ecosystems. We care about sound statistical methodology and good software that is useful for answering broad statistical questions in computational biology and microbial ecology.
What infrastructure, programs and tools are used in your group? We use R, Python, (and MATLAB) for software development, and use GitHub for software deployment and versioning. Group communication is decentralized via Slack and Mattermost. We have (shared) office spaces at LMU Munich (City center) and Helmholtz Munich (in the North of Munich).
What could a guest researcher learn in your group? How could he or she support you in your group? High-dimensional statistics concepts, data analysis workflows for microbiome and microbial data, journal club covering state-of-the-art concepts ranging from experimental high-throughput biology to deep learning.

Julien Gagneur
Computational Molecular Medicine
Prof. Dr. Julien Gagneur
Three-sentence summary of your group's research: Our goal is an improved understanding of the genetic basis of gene regulation and its implication in diseases. To this end, we employ AI and statistical modeling of 'omic data and work in close collaboration with experimentalists. We are both based at the TUM and HMGU.
What infrastructure, programs and tools are used in your group? We work with python, ML libraries (pytorch, etc.) and R/Bioconductor.
We have developed multiple software for regulatory genomics and genetic diagnostics including :
- API and repos for trained ML models in genomics Kipoi
- sequence-based model of splicing MMSplice (GitHub)
- Base pair resolution modeling of genome-wide assays BPnet (Article regarding the topic)
- Omics based diagnosis of rare disorders: OUTRIDER, FRASER, DROP: (Protocol regarding the topic)

Niki Kilbertus
Ethics in Systems Design and Machine Learning
Ansprechpartner
Three-sentence summary of your group's research: Our main research interests include causality, interpretable dynamical systems modeling, as well as machine learning systems that interact with humans, where we focus on reliable, fair and socially beneficial systems.
What infrastructure, programs and tools are used in your group? We make use of high performance CPU and GPU compute clusters (via Slurm) and regularly use ML frameworks (mostly jax and pytorch) together with the standard Python data analysis and visualization stack (scikit-learn, pandas, numpy, matplotlib, etc). On the theory side, we are interested in (partial) identifiability of causal effects in complex data modalities as well as in the identifiability and estimation of dynamical systems (ODEs, PDEs) from observational data.
What could a guest researcher learn in your group? How could he or she support you in your group? You can learn about the latest and greatest in causal learning and dynamic systems modeling as well as how to train both small and (very) large ML models on one of the largest GPU clusters in Europe. You can apply cutting-edge models to novel bio-medical data to push the boundaries of machine learning powered scientific discovery, drug development, and understanding of health and disease. You can experience working right at the intersection of theory and application with lots of freedom to explore either direction to whatever extent suits you.

Michael Schloter
Comparative Microbiome Analysis
Ansprechpartner
Three-sentence summary of your group's research: The human microbiome is a key component for our health. It is strongly influenced by environmental microbiota, which interact with the microbiome of barrier organs like skin or respiratory system. As a consequence, the reduced microbial diversity in the environment, resulting from climate- and global change, strongly impacts human – environment interactions, resulting in an increase in environmental diseases and infections. According to the planetary health concept the prevention of such diseases requires strategies which increase biodiversity in the environment.
We identify key microbiota from the environment, which trigger our health, develop strategies to promote the abundance of those microbiota in urban and indoor environments and analyze consequences for our health.
What infrastructure, programs and tools are used in your group?: We do next generation sequencing of microbiomes using metagneomics approaches from various sources and perform high throughput bioinformatics including KI based tools to reconstruct genomes of microborganisms.
What could a guest researcher learn in your group? How could he or she support you in your group?: In silco genome assembly of microbiota from metagenomics data and functional predications.

Vincent Fortuin
Efficient Learning and Probabilistic Inference for Science
Ansprechpartner
Three-sentence summary of your group's research: Our group focuses on the interface between Bayesian inference and deep learning with the goals of improving robustness, data-efficiency, and uncertainty estimation in these modern machine learning approaches. While deep learning often leads to impressive performance in many applications, it can be over-confident in its predictions and require large datasets to train. Especially in scientific applications, where training data is scarce and detailed prior knowledge is available, insights from Bayesian statistics can be used to drastically improve these models. Important research questions include how to effectively specify priors in deep Bayesian models, how to harness unlabeled data to learn re-usable representations, how to transfer knowledge between tasks using meta-learning, and how to guarantee generalization performance using PAC-Bayesian bounds.
What infrastructure, programs and tools are used in your group? We make use of high-performance CPU and GPU compute clusters (via Slurm) and regularly use deep learning frameworks (mostly PyTorch and JAX) together with the standard Python data analysis and visualization stack (scikit-learn, pandas, numpy, matplotlib, etc). On the theory side, we are interested Bayesian model selection, approximate Bayesian inference, and PAC-Bayesian generalization bounds.
What could a guest researcher learn in your group? How could he or she support you in your group? You can learn about the latest and greatest in Bayesian machine learning as well as how to train both small and (very) large deep learning models on one of the largest GPU clusters in Europe. You can apply cutting-edge ML models to a range of scientific data to push the boundaries of ML-powered scientific discovery, drug development, and understanding of health and disease. You can experience working directly at the intersection of theory and application with lots of freedom to explore either direction to suit your interests.

{kind=link}